Coqui/XTTS is a library for advanced Text-to-Speech generation.
The model XTTSv2 is a Voice generation model that lets you clone voices into different languages by using just a quick 6-second audio clip. There is no need for an excessive amount of training data that spans countless hours.
https://github.com/coqui-ai/TTS
https://huggingface.co/coqui/XTTS-v2
Configure Coqui for Voxta
Terms of Service: Toggle switch to agree to Coqui’s Terms of Service before using the library.
Default Female Voice: Dropdown to select the default voice for female characters, with an example voice file provided.
Default Male Voice: Dropdown to select the default voice for male characters, with an example voice file provided.
Users have the option to use their own voice samples. To do this, custom .wav files should be placed in the ..Data\Audio\VoiceSamples directory. Once the files are in the correct location, they can be selected as the default voice for either male or female characters within the Coqui settings panel. This customization allows for a more personalized experience when using the text-to-speech features of the platform.
Use CUDA: Toggle switch to decide whether to use the GPU for voice processing. If turned off, the CPU is used instead.
Use DeepSpeed: Toggle switch to enable DeepSpeed, which significantly accelerates voice generation.
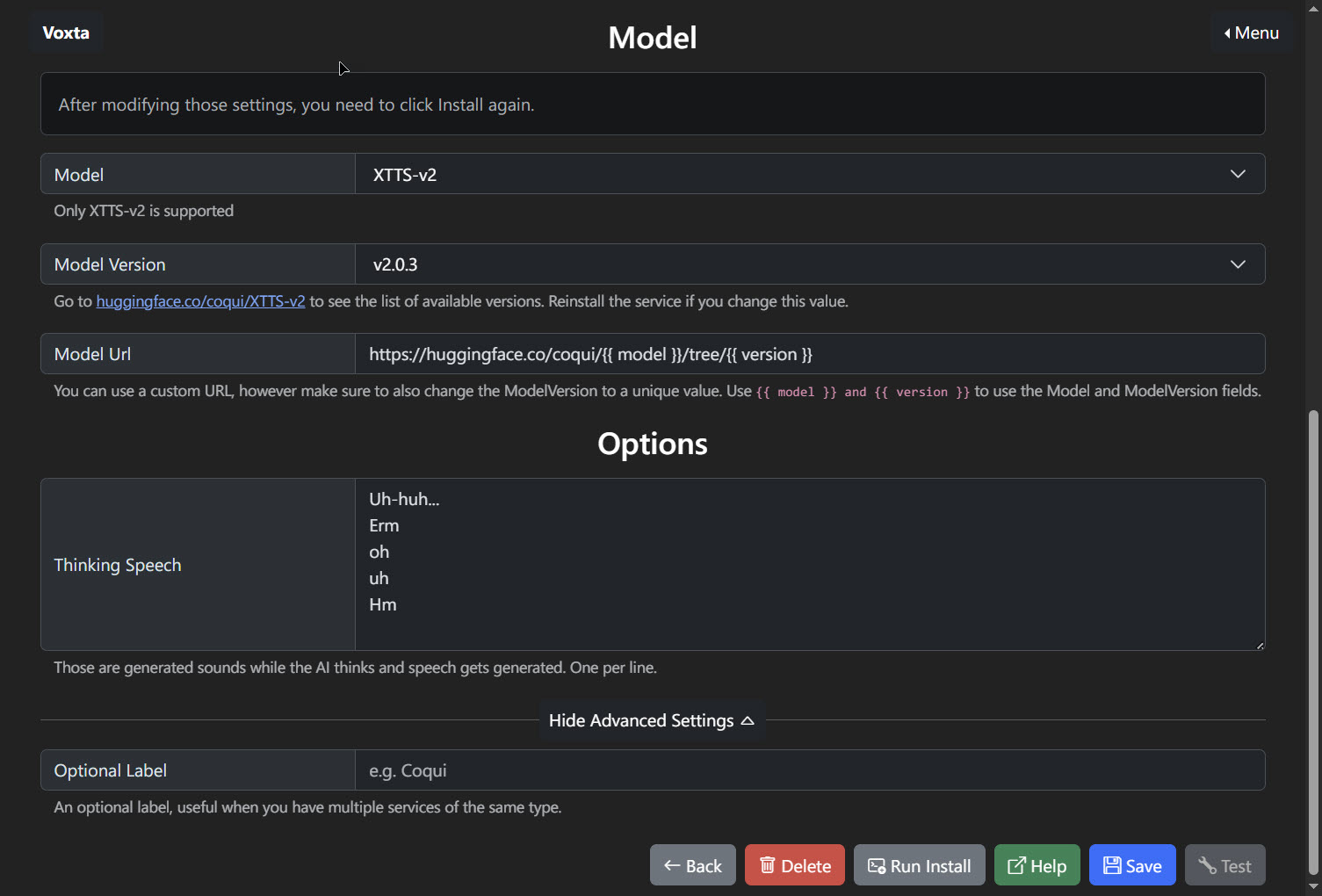
Model: Only XTTS-v2 is supported, indicating a specific text-to-speech model compatibility.
Model Version: allows users to select from a list of available text-to-speech models. Each selection corresponds to a specific version of a TTS model provided by the service. Once a model version is chosen from this list, users may need to install or update the service to integrate the new version into Voxta’s functionality.
Model URL: A templated URL is provided to fetch the model from Hugging Face. Users can customize this URL, ensuring the placeholders for model and version are correctly replaced.
Thinking Speech: Users can input interjections for the AI to use while processing speech, enhancing the naturalness of the AI’s interaction.
Optional Label: Allows users to assign a unique label to the service configuration, useful in distinguishing between multiple services.